“It should be noted that the automobile was also invented by pedestrians. But, somehow, motorists quickly forgot about this.” – Ilya Ilf and Evgeny Petrov, The Golden Calf
Why it is not as simple as it seems
Data Science, Artificial Intelligence and Machine Learning are the terms that are frequently used and often used interchangeably (as I did in my recent post). Yet, there are clear cut differences between these terms, which are useful to understand when applying for jobs or participating in an intelligent discussion. I start with pointing out several common misnomers, and then provide a bit of historical and theoretical background that my own view is based upon.
Let’s not be literal
Saying that Data Science is “a science about collecting and analyzing data” at worst borders on nonsense while at best provides a definition that is too general to be of any practical use. Moreover, it is easy to convince oneself that such a definition is wrong: Indeed, a career scientist with several decades of experience in analyzing, e.g., biological or chemical data is not a data scientist. A quick look at job announcements will show that a “Data scientist” is often required to have very specific software skills that our scientist probably does not possess. In the same time, these job announcements might be very light on the skills that the real scientists consider necessary for working with and analyzing data.
When your only tool is a hammer, every problem looks like a nail
Another common trap is looking only at the aspect of each of these fields that one is most familiar with, e.g., the algorithms used therein. Some of these algorithms are frequently associated with Data Science (e.g., various regression and classification methods), others fall in the domain of Artificial Intelligence (e.g., reinforcement learning), and the more complicated ones are classified as Machine Learning (which is certainly true for neural networks, but not necessarily so for ANOVA or linear regression). Depending on your experience you may be tempted to say that one field is merely a subset of another or discuss the overlap between the two, whereas in reality you will be talking only about one aspect of the whole.
Coming from a different background, I could say that all the three are just a modern variation of the good old statistics, but this would be doing an injustice towards the mathematical and computational developments of the last few decades.
Brevity is the sister of the talent
Finally, there are plenty of long-winded answers to this rather simple question. Indeed, some people believe that giving lots of “simple” examples makes things easier. The problem is that that no one listens to such explanations. Once you said “for example…” you’ve lost your audience (such as a recruiter or an HR person). The answer I provide below may be not the unique one, and not the most generally accepted one, but it is an operational answer, and I will try to summarize it in a few short phrases.
REMARK: I will further occasionally refer to Data Science, Artificial Intelligence and Machine Learning by their initials: DS, AI and ML.
Collecting and analyzing data over centuries
Collecting and analyzing data is probably as old as the human civilization – certainly preceding the emergence of DS, AI and ML as we know them.
Year’s length
A good example of the progress in data collection is the estimate of the length of a year over the centuries. That seasons repeat themselves after approximately twelve moon cycles and that one moon is about 29 days was probably noted by the early humans and possibly also by the Neanderthals. Such an estimate however errs by two-three weeks every year, so it was a great improvement when, in the 3rd millennium BCE, the Babylonian astronomers estimated the year’s length to be 360 days. My guess is that in absence of a natural phenomenon marking a new year (such as sunrise for the new day or new moon for the month) they had to spend a few decades making daily records of seasonal phenomena and then calculating the average. The remaining generations of the Babylonian priests probably continued making the records in order to reduce the estimation error.
Ancient Greeks and Romans improved the estimate by correlating the seasonal phenomena to much more regular cycles of stars and planets, producing the estimate of 365.25 days, which was codified in the Julian Calendar that the Orthodox Church still continues to use (this is why the Russian “October Revolution” took place in November). It took another millennium and a half till the observations with high-precision navigation instruments ushered in another reform, producing the Gregorian Calendar, where the leap year is skipped every four hundred years.
While we still talk about stars, let us mention a well-known data science project carried out by Tycho Brahe and his student Johannes Kepler: Brahe spent good three decades making observations of one and the same supernovae star. His data were later analyzed by Kepler resulting in the Kepler laws of stellar motion.
Back to the grammar school
Today learning about parts of speech and conjugations is a thing for an elementary school or a beginners’ language course for foreigners. Yet, once upon a time these things were unknown. The notions of grammar known to the speakers of the major European languages come from the observations made over centuries by ancient Greeks annd Romans, who took great interest in speaking and writing beautiful prose and poetry.
A more well-defined project was carried between 6th and 10th centuries by the group of Jewish scholars, known as the Massoretes of Tiberia. They analyzed a well-defined corpus of texts written in Hebrew (including the Jewish Bible, Talmud and some others) and produced a complete set of rules governing the grammar and the pronunciation of the Hebrew texts. Their data were so convincing that they even dared to point out the places in the Bible where incorrect grammatical forms were used, although they understandably abstained from correcting the holy text. A similar (and technically much earlier) example of such work was carried out by an Indian poet Pāṇini in the 6th century BCE to codify the grammar of Sanskrit.
As a particular example of a pre-NLP (natural language processing) project let us mention the work of Jacob Grimm (the elder of the Grimm Brothers), who collected and analyzed the data from a few dozen dialects of German and came up with the “Grimm law”, describing how the pronunciation of sounds various sounds evolves over time. This work has served as the basis for the historical linguistics.
Statistics: science about collecting and analyzing data
The real boom of data analysis happened in the XIXth and XXth centuries as a result of the technological revolution and emergence of sciences, such as physics, chemistry, evolutionary biology, etc. Any scientific field prides itself as being grounded in collecting and analyzing data (although this claim is somewhat strained when it comes to social sciences and the computer science). With the time studying and using the scientific methods of analysis became a science in itself, known under the name of *statistics*.
Data collection in statistics is known as *experiment design* or *study design*. The goal of the study design is not simply obtaining and recording data, but doing it in an unbiased manner, i.e. in a way permitting reliable analysis and conclusions.
Data analysis is the mathematically and computationally heavy part. The collected data can be used for *parameter estimation*, such as in our earlier example about estimating the length of a year on the basis of astronomical and seasonal observations. Another frequent application is *hypothesis testing*, where the data is used to confirm or disprove a guess, such as, e.g., a grammatic rule.
Note that the hypothesis itself and the model, a parameter of which is being estimated, are generated by the humans who perform data collection and analysis. Likewise, it is up to the humans to to decide whether the hypothesis was proved, whether the parameter estimation was satisfactory, how the two can be used in future, and what could be done about the bad results. We will refer to this as making *decisions* based in the results of the analysis.
How is data science different from statistics?
The information age has brought two important developments:
First of all, it has made large (or even “huge”) quantities of data readily available for the analysis. Partly, because data collection has become easier, partly because new interesting datasets has arisen, such as the records of the internet traffic, purchases, financial transactions, etc., and partly because the data are now recorded in computer-friendly form (rather than in paper log-books) and therefore easily accessible for the analysis.
The second important development is the increase in pure computational power, which made it possible to use the methods of statistical analysis that were previously considered as impractical (as well as creating new computationally heavy methods).
Heavy reliance on the storage capacity and the compuational power of modern computers is what distinguishes Data Science from conventional statistics. This explains why scientists with experience in collecting and analyzing data often do not cut the mark as data scientists, due to their lack of training in computer science.
Artificial intelligence
Data Science is a quantitative improvement of the two areas of statistical analysis that had already been somewhat routine/technical: data collection and the calculations related to parameter estimation or hypothesis testing. It doesn’t touch the areas that are essentially human activity: formulating the hypothesis to test (or a model the parameters of which are estimated) and making the decisions based on the results of the analysis.
Mimicking the human capacity for hypothesizing and decision-making is what we call Artificial Intelligence. Note that AI is not necessarily built atop the Data Science; in fact, it can rely on very little data and little analysis. For example, I have a Roomba 700 robotic vacuum cleaner – the one that rolls along the floor and changes the direction every time when it hits an obstacle. It is even more sophisticated than that: it adjusts the time of vacuuming to the dirtiness of the floor and, if some spot seems particularly dusty, it will spend more time cleaning this particular spot. Clearly it makes decisions and acts upon them. However, these decisions are based on rather simple inputs from its sensors
(in terms of the quantity of data). Neither does it learn the layout of my apartment, that could help it in the next cleaning session.
Self-driving cars and even the language processing systems are sometimes not much more sophisticated than that, although they do give the impression of being sophisticated to the laymen. For example, one of the earliest language processing systems was built to simply paraphrase the sentences entered by the user. Yet many test users thought it capable of understanding them better than their friends or relatives. For example:
* Computer: How are you?
* User: I am sad.
* Computer: why are you sad?
* User: My cat died.
* Computer: How did it die?
(Indeed, this is the strategy often used by psychologists to make people open up.)
How does the machine learning fits in?
The algorithms used for data analysis in Data Science as well as the decision-making algorithms used in AI form together what is called Machine Learning. Strictly speaking, word “machine” implies the computationally heavy techniques, however one often includes into Machine Learning the basic techniques such as linear regression or PCA. This is partly motivated by the mathematical convenience of treating together the modern methods and those of good old classical statistics.
The short answer
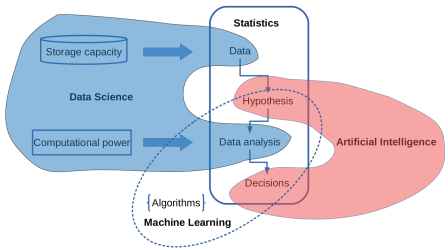
I have tried to present above a coherent view of the interrelations between Data Science, Artificial Intelligence, Machine Learning and traditional Statistics. These interrelations are summarized below, as well as in the following figure.
* Statistics is the discipline about collecting and analyzing data. It leaves to human to make hypotheses and judge the results.
* Statistics becomes Data Science when it deals with huge quantities of data and computationally intensive estimation/testing procedures.
* Artificial Intelligence makes judgements/decisions on the basis of the results of a statistical analysis.
* Machine learning is the collection of the computational procedures used for data analysis in Data Science and for making decisions in the context of Artificial intelligence.